
ChatGPT Bilgi Kesintisi: 2026'da Marka Etkinizi Yönetmenin Yolları
Yeni bir ürün piyasaya sürüyor, konumlandırmanızı güncelliyor, basın bültenleri yayınlıyor ve ardından ChatGPT'ye şirketinizin tam olarak ne sunduğunu soruyorsunuz. Gelen cevap kusursuz görünebilir. Ancak çoğu zaman baştan sona yanlıştır.
Belki kullanımdan kaldırdığınız eski bir versiyonu anlatır. Belki de yeni lansmanınızı tamamen yok sayar ve şu an lideri olduğunuz kategoride eski bir rakibinizi öne çıkarır. Alıcılar, potansiyel satıcıları değerlendirmek için yapay zeka yanıtlarını kullanırken bu durum basit bir "model hatası" olmaktan çok daha fazlasıdır.
Markanızın şu anki gerçek durumu ile bir Büyük Dil Modelinin (LLM) markanız hakkında hatırladıkları arasındaki bu uçurum, ChatGPT bilgi kesintisi kavramının ciddi bir işletme sorununa dönüştüğü yerdir. Bu durum lansman görünürlüğünüzü, arama yolculuklarını ve müşterilerin kendi içlerinde paylaştıkları marka bilginizin tutarlılığını doğrudan etkiler.
Her Pazarlamacının Korkulu Rüyası
2026'nın başlarında ekibinizle devasa bir ürün güncellemesi yaptığınızı varsayalım. Satış dokümanları yenilendi, ana sayfa baştan tasarlandı ve yeni kullanım senaryoları yayına alındı. Bir hafta sonra ekipten biri ChatGPT'yi açıp basit bir soru sorar: "Bu şirket ne yapıyor ve son yenilikleri neler?"
Gelen cevap tamamen eski hikayenizi anlatır.
İşte tam bu anda sorunun ciddiyeti anlaşılır. Yapay zeka sadece bir detayı atlamakla kalmaz; markanızı artık var olmayan eski bir versiyonuyla adeta yeniden yazar. Eğer model eski eğitim verilerine dayanıyorsa, en son ürününüz, fiyatlandırma mantığınız, entegrasyonlarınız veya liderlik değişiklikleriniz yok sayılır. Bazı durumlarda model bu boşluğu kendinden emin bir tahminle doldurur ki bu, bilmediğini itiraf etmesinden çok daha tehlikelidir.

Bu Neden Normal Bir Arama Hatasından Daha Kötü?
Geleneksel SEO ekipleri gecikmelere alışıktır. Bir sayfanın sıralama alması zaman alabilir. Bir tarayıcının sayfayı yeniden ziyaret etmesi vakit alır. Ancak yapay zeka cevapları, satın alma yolculuğunu inanılmaz derecede sıkıştırır. Bir müşteri adayı tek bir soruyla anında sentezlenmiş bir pazar görünümü elde eder.
Eğer bu görünüm güncel değilse, aynı anda birkaç kritik sorun ortaya çıkar: - Lansmanınız görünmez olur: Ürün güncellemesi sitenizde mevcuttur ancak alıcının gördüğü yanıtta yer almaz. - Eski mesajlar varlığını sürdürür: Modelin eski verileri hatırlaması daha kolay olduğu için eski konumlandırmanız sürekli tekrarlanır. - Güven zedelenir: Müşteriler sitenizle yapay zeka özetini karşılaştırır ve hangisinin doğru olduğunu sorgular. - Rakipler avantaj sağlar: Eski ama daha çok indekslenmiş bir rakip, ürününüz daha güçlü olsa bile yapay zekanın gözünde "daha güncel" görünebilir.
Pratik Kural: Marka görünürlüğünden sorumluysanız, yapay zeka yanıtlarını sadece arada bir test edilecek bir yenilik olarak değil, sürekli izlenmesi gereken aktif bir yüzey olarak kabul edin.
Bilgi Kesintisi Nedir?
Bir bilgi kesintisi (knowledge cutoff), bir LLM'in yalnızca eğitim verilerine dayanarak sahip olduğu entegre farkındalığın sona erdiği tarihtir. Bu tarihten önceki köklü konular hakkında model hızlı ve kendinden emin yanıtlar verir. Ancak daha sonra gerçekleşen bir ürün lansmanı, fiyat değişikliği veya yeniden markalaşma sorulduğunda, yanıtın kalitesi ciddi şekilde düşer.
Sistemlerin nasıl çalıştığını operasyonel olarak üç gruba ayırabiliriz:
- Arşivlenmiş Bilgi: Köklü konuları ve uzun süredir var olan marka gerçeklerini harika açıklar. Ancak yeni lansmanları, mesajlaşma değişikliklerini ve pazar kaymalarını kaçırır.
- Canlı Web Taraması (Retrieval): Yeni sayfaları ve zamana duyarlı detayları çeker. Fakat bazı sayfaları kaçırabilir, bağlamı yanlış okuyabilir veya zayıf kaynaklara atıf yapabilir.
- Tarama Destekli LLM: Önceden öğrenilmiş bilgiyi yeni sayfalarla birleştirir. Eski varsayımlarla kısmi yeni kanıtları birbirine karıştırma riski taşır.
SEO ekiplerinin odaklanması gereken asıl alan bu son maddedir. Bir model kategorinizi eğitim verilerinden bilir, ardından yeni bir makale, bir ürün sayfası ve üçüncü taraf bir bahsedilme bulur. Eğer bu kaynaklar eksik veya tutarsızsa, nihai cevap çok profesyonel görünmesine rağmen markanızın hikayesini yanlış anlatabilir.
Neden Kesintiler Var?
Model sağlayıcıları, web her değiştiğinde çekirdek eğitimi yenilemezler. Eğitim süreci pahalı, yavaş ve operasyonel olarak çok ağırdır. Üstelik güncellenmiş bir modeli piyasaya sürmeden önce kalite ve güvenlik testleri yapılmalıdır. Bu nedenle pazarın mevcut durumu ile modelin doğal olarak bildikleri arasında her zaman bir gecikme yaşanır.
Web taraması (browsing) bu soruna yardımcı olsa da, tarama kalıcı bir hafıza demek değildir. Alınan sayfalar sadece o oturum için geçici bir bağlamdır ve eğitim sırasında öğrenilen kalıplarla aynı ağırlığı taşımazlar. Pratikte bu, 2026'da çıkardığınız bir özelliğin bir soruda görünüp diğerinde kaybolabileceği anlamına gelir.
En Doğru Analoji: Marka Hafızasına Karşı Güncel Brifing
SEO çalışmaları için en faydalı analoji "ansiklopediye karşı internet" değildir. Asıl analoji "marka hafızasına karşı güncel brifing" olmalıdır.
Eğitilmiş bir modelin marka hafızası vardır; şirketinizin eğitim verilerindeki halini hatırlar. Veri çekme (retrieval) ise, modele konuşmadan hemen önce sunulan güncel bir brifing dosyası gibidir. Eğer bu dosya zayıf, güncel değil veya önemli sayfalardan yoksunsa, model kendi eski hafızasına geri döner.
Ekiplerin genellikle düştüğü tuzak "ChatGPT bizi biliyor mu?" diye sormaktır. Bunun yerine şu sorular sorulmalıdır: - Model markanın hangi versiyonunu biliyor? - Hangi iddialar eğitimden, hangileri canlı taramadan geliyor? - Hangi satın alma komutları (promptlar) eski açıklamalarınızı tetikliyor?
2026 İçin Bilinen LLM Bilgi Kesinti Tarihleri
Günlük üretken arama motoru optimizasyonu (GEO) çalışmaları için bir kesinti tarihinin değeri basittir: O tarih, modelin en yeni içeriklerinizi dışarıdan yardım almadan bileceğini varsaymayı bırakmanız gereken noktadır.
OpenAI'nin takvimi tarihsel olarak kesintiler ve sürümler arasında 6-18 aylık boşluklar bırakmış ve verilerin geri çağrılmasında %95 oranında kesinti öncesi verilere dayanmıştır.
2026 itibarıyla bazı önemli modellerin durumu şöyledir: - GPT-4: Eylül 2021 (Temel eğitim kesintisi) - GPT-4 Turbo: Aralık 2023 (Gecikmeyi azaltıp güncelliği artırdı) - GPT-4o: Ekim 2023 (2026 itibarıyla ChatGPT Plus'ta varsayılan, aktif tarama desteği var) - GPT-5 Serisi (5.2 ve 5.4): Ağustos 2025 (2025 sonu-2026 başı sürümlerinin temel kesintisi)
Eğer lansmanınız Ekim 2023'ten veya Ağustos 2025'ten sonraysa, temel modelin dışarıdan yardım almadan (tarama tetiklenmeden) bunu bilmesini beklememelisiniz. Yeni içerikleriniz nesiller arasında kaldıysa, bir yapay zeka yüzeyi sayfanızı alıntılarken diğeri tamamen görmezden gelebilir.
Doğruluk ve Marka Görünürlüğü Üzerindeki Gerçek Etki
Bir kesintinin doğrudan maliyeti sadece modelin yeni gerçekleri kaçırması değildir. Daha büyük sorun doğruluk erozyonudur. Bir konu modelin zaman sınırına yaklaştıkça veya geçtikçe yanıtlar güvenilmez hale gelir. Yapılan bir analizde, belirli bir modelin eski tarihlerdeki olaylar için %91.69 doğruluk sağlarken, kesinti tarihine yaklaştıkça bu oranın ciddi şekilde düştüğü görülmüştür.
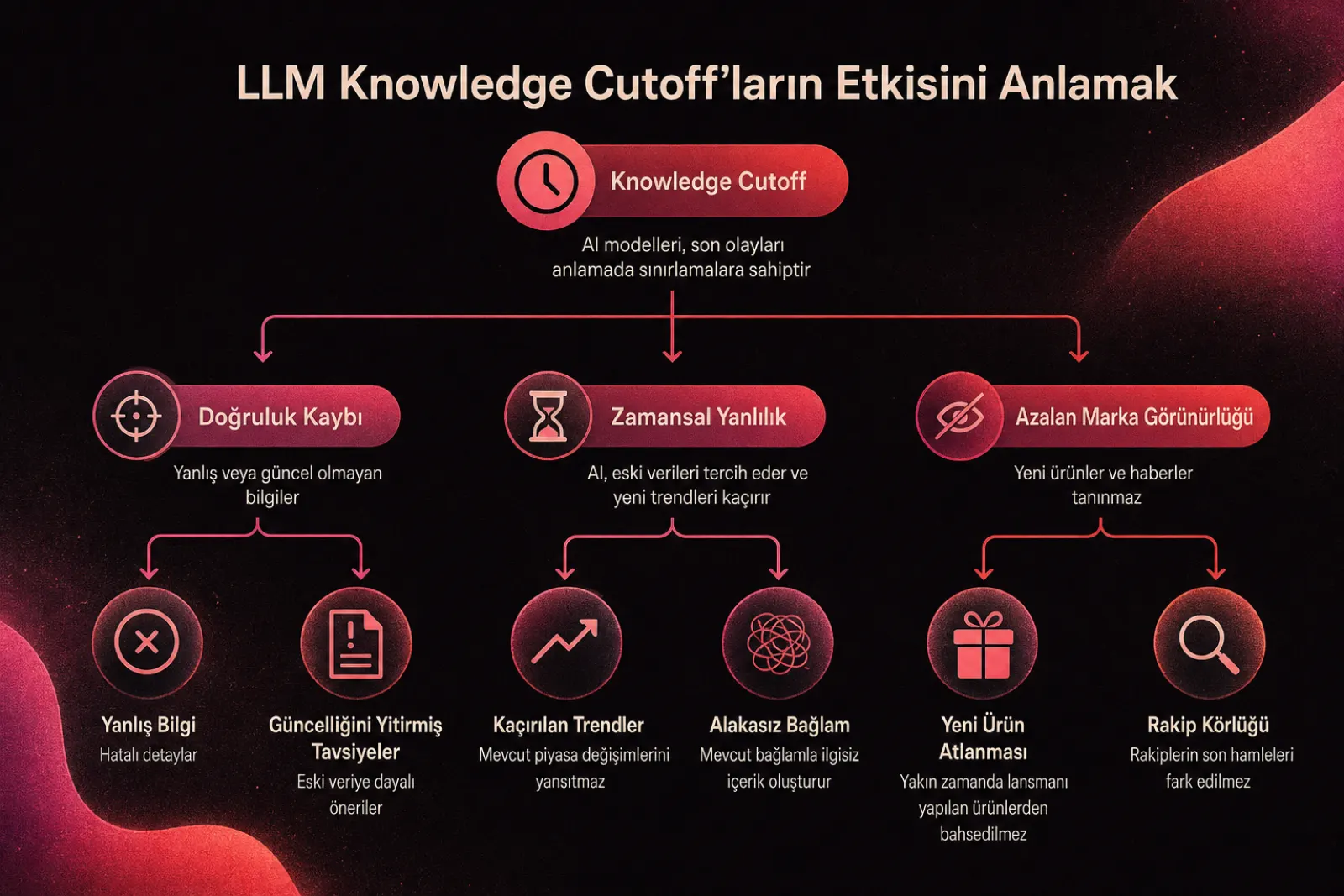
Zamansal Ön Yargı ve Kategori Önerileri
Bir LLM sadece yeni gerçekleri unutmakla kalmaz, kesintiden önce kurulan düzeni kayırmaya eğilimlidir. Bu durum zamansal ön yargı (temporal bias) yaratır. Eski markalar ve eski anlatılar, yapay zeka yanıtlarını olması gerekenden çok daha uzun süre domine edebilir.
Sizin en güncel kanıtlarınız yok sayılırken rakibinizin eski ayak izi geniş bir şekilde temsil ediliyorsa, model tarafsızmış gibi görünse de aslında pazarın sadece en eski versiyonuna yaslanıyordur.
Huninin Her Aşamasında Kayıp
Eski bir yapay zeka yanıtı, müşteri hunisini birçok noktadan bozabilir: - Erken araştırma: En yeni teklifiniz atlanır, yanlış kullanım senaryoları için kısa listeye girersiniz. - Kategori karşılaştırması: Eski mesajlarınız tekrarlanır ve farklılıklarınız silikleşir. - Tedarikçi doğrulaması: Eski iddialar yüzeye çıkar ve daha demo aşamasına gelmeden güven kaybı yaşanır. - Kurum içi paylaşım: Eski özetler üretilir ve alıcı komite içinde yanlış bilgiler yayılır.
Veri kalitesi bu yüzden çok önemlidir. Eğer ana sayfalarınızda tutarsız isimlendirmeler veya zayıf güncelleme sinyalleri varsa, canlı veri çekme (retrieval) sistemlerinin markanızı şu anki haliyle konumlandırması neredeyse imkansızdır.
Bir LLM'in Bilgi Kesintisini Kendi Başınıza Nasıl Tespit Edersiniz?
Pazarlamacılar genellikle kesinti sorunlarını en kötü anda fark ederler. Model markanız hakkında pürüzsüz bir yanıt verir ancak aylar önceki halinizi anlatır. Modeli test etmek için kendi sitenizden ve güncel haberlerinizden doğrulayabileceğiniz gerçeklere dayalı küçük bir komut seti kullanmalısınız.

Sınırları Ortaya Çıkaran Komutlar
Yakın zamanda değişen ve alıcılar için önemli olan gerçeklerle başlayın. Yeni bir ürün serisi, fiyat değişikliği, şirket satın alımı veya pazar genişlemesi ideal test konularıdır.
Şu komutları kullanın: 1. "Bu şirketin 2026'da piyasaya sürdüğü en yeni ürün nedir?" 2. "Bu markanın mevcut konumlandırmasını özetleyin ve son değişiklikleri dahil edin." 3. "[Marka] ve [Rakip]'i en son tekliflerine göre karşılaştırın." 4. "Bu cevap için hangi bilgileri kullanıyorsunuz, webden güncel veri çektiniz mi?"
Eğer yanıt kendinden emin ama eskiyse, model eski eğitimine dayanıyordur. Yanıt doğru ve taze referanslarla doluyorsa, tarama (browsing) araya girmiş ve güncellemeyi sağlamıştır. Modelin kendi kesinti tarihi hakkındaki açıklamalarına çok güvenmeyin; zaman damgalı sorulara verdikleri tepkiler her zaman daha net bir sinyaldir.
Saha Notu: Hafıza ile canlı veri arasındaki farkı görmek için aynı soruyu iki kez sorun. İkinci soruda "Mevcut web bilgilerini kullanarak 2026'daki son haberler nelerdir?" deyin. Eğer model ilkinde atladığı lansmanı ikincisinde buluyorsa, temel eğitimde o bilgiye sahip olmadığı teşhisini koyabilirsiniz.
Kesinti Sorunlarını Azaltma ve İzleme Stratejileri
Bilgi kesintilerinin normal olduğunu kabul ettikten sonra süreci operasyonel hale getirmelisiniz. Kesintiyi "düzeltemezsiniz" ancak etkisini azaltabilir ve yanıtlar gerçeklikten saptığında size haber verecek sistemler kurabilirsiniz.
Sadece Sıralama İçin Değil, Tarama (Retrieval) İçin Yayın Yapın
İçerik ekipleri hala sadece mavi link trafiği (klasik SEO) için yayın yapıyor. Yapay zeka görünürlüğü için içeriklerinizin yorumlanmasının ve alıntılanmasının çok kolay olması gerekir. - Yeni gerçeği net bir şekilde belirtin: Ürün sürümünü veya fiyat değişimini karmaşık cümleler olmadan verin. - Tutarlı varlık dili kullanın: Aynı özelliği sayfalar arasında üç farklı isimle adlandırmayın. - Kavramları destekleyin: Modele güncellemenin neden önemli olduğunu anlaması için yeterli çevresel detay sunun.
Ana Sayfalarınızın Etrafında "Güncellik Varlıkları" Oluşturun
Kalıcı bir sayfayı (örneğin ana ürün sayfası), onu destekleyen güncel bir varlıkla (sürüm notu veya basın duyurusu) eşleştirmek harika bir pratiktir. Bu yaklaşım, tarayıcılara net bir tazelik sinyali verir ve kategori çerçevelerini güçlendirir.
Komutları Alıcıların Sorduğu Gibi Tasarlayın
Sistemlerinizi test ederken "Bu modelin eğitim kesintisi nedir?" gibi yapay sorular sormayın. Gerçek ticari niyeti yansıtan komutlar kullanın: - "[İşlem] için en iyi platform hangisidir?" - "[Rakip] için en iyi alternatifler nelerdir?" - "[Marka] ve [Rakip] arasındaki şu anki fark nedir?"
Bir İzleme İş Akışı Kurun
Düzenli bir iş akışı şu adımları içermelidir: 1. Markalı, markasız, karşılaştırmalı ve güncelliğe duyarlı komut setleri oluşturun. 2. Sabit marka değerleriniz ile 2026 lansman mesajlarınızı aynı sepette değerlendirmeyin. 3. Sadece bahsedilmelere değil, hangi kaynakların alıntılandığına (citations) odaklanın. 4. Rakiplerin aynı yanıtlardaki varlığını sürekli kontrol edin. Model sizin güncellemenizi kaçırıp rakibi sürekli alıntılıyorsa ortada bir keşfedilebilirlik sorunu vardır.
Kesinti yönetimini bir rekabet avantajı olarak gören markalar, yapay zeka yanıtlarının müşteri şikayeti yaratacak kadar yanlış olmasını beklemezler. Sınırları bilir, makine tarafından okunabilir güncel kaynaklar yayınlar ve alıcıların kullandığı sorgularda var olup olmadıklarını haftalık olarak test ederler. ChatGPT bilgi kesintisi herkesi etkiler; ancak zafer, bu sapmayı ilk fark eden ve arama motorlarına işleyebilecekleri en temiz ve güncel materyali veren ekibin olur.